
Vous lancez beaucoup de tests A/B et vous consommez 100 % de votre trafic disponible ? Le nombre d’hypothèses d’optimisation s’accumule dans votre roadmap d’optimisation et on vous en demande toujours plus ? Lancer plusieurs tests A/B en parallèle et sans règle de ciblage particulière peut-être tentant. Que ce soit dans ce contexte ou une simple question de ciblage, quels sont les risques pour les résultats de vos tests A/B ?
Une analyse des résultats de tests A/B complexe
Impact des tests A/B entre eux
Les données de vos tests A/B se polluent probablement entre elles et c’est quasi impossible de mesurer l’impact de cet effet. Dans ce contexte, vous serez incapable d’analyser les résultats et d’affirmer qu’un test A/B est gagnant ou perdant en toute confiance.
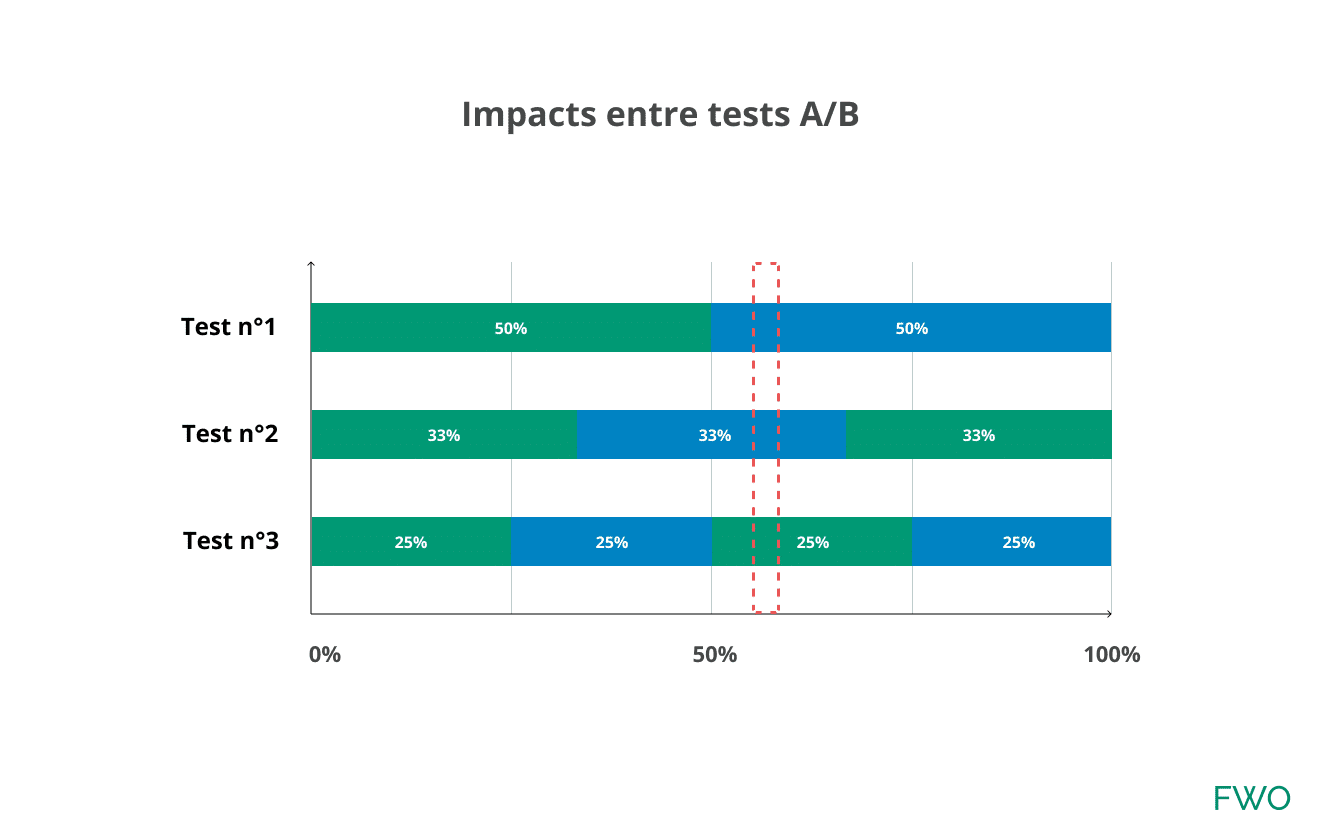
Prenons cet exemple : vous lancez 3 tests A/B sur différents périmètres et sans condition de ciblage particulière. À travers sa navigation, l’utilisateur se voit attribuer une combinaison de test. Comment définir la performance des utilisateurs (zone rouge) sur chacun des tests A/B ?
Que se passe-t-il lorsque vous analysez les résultats du test n° 1 ?
Vous souhaitez analyser les résultats du test A/B n° 1 dans votre dashboard. Ces chiffres contiennent en partie les chiffres des 2 autres tests A/B et peuvent avoir un impact.
Plusieurs théories sont possibles :
1) Pas d’impact : les tests A/B sont totalement décorrélés et n’ont pas d’impact de performance entre eux (monde parfait).
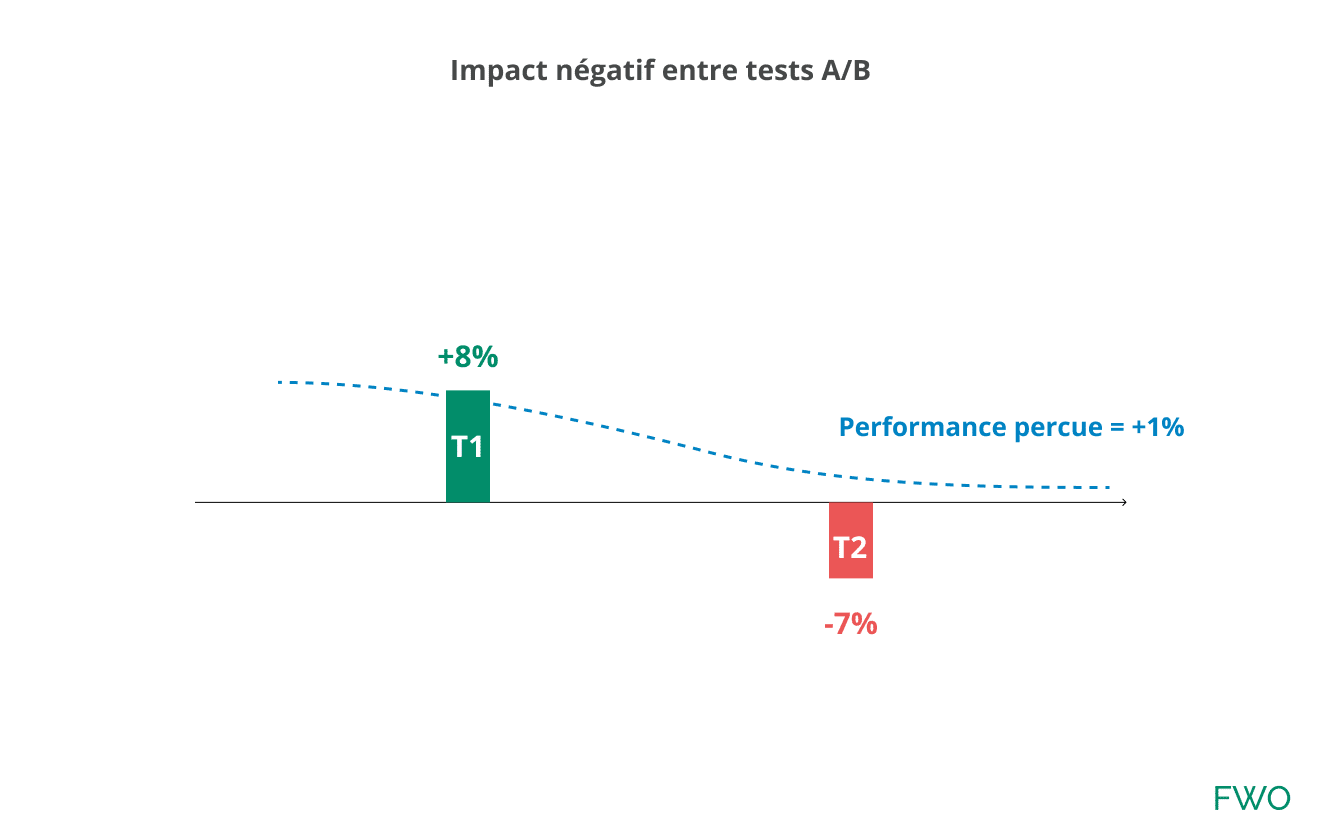
2) Impact négatif : le test A/B n° 2 est négatif et réduit les performances du test n° 1. La performance perçue sera proche de +1 % pour l’un ou l’autre des tests A/B :
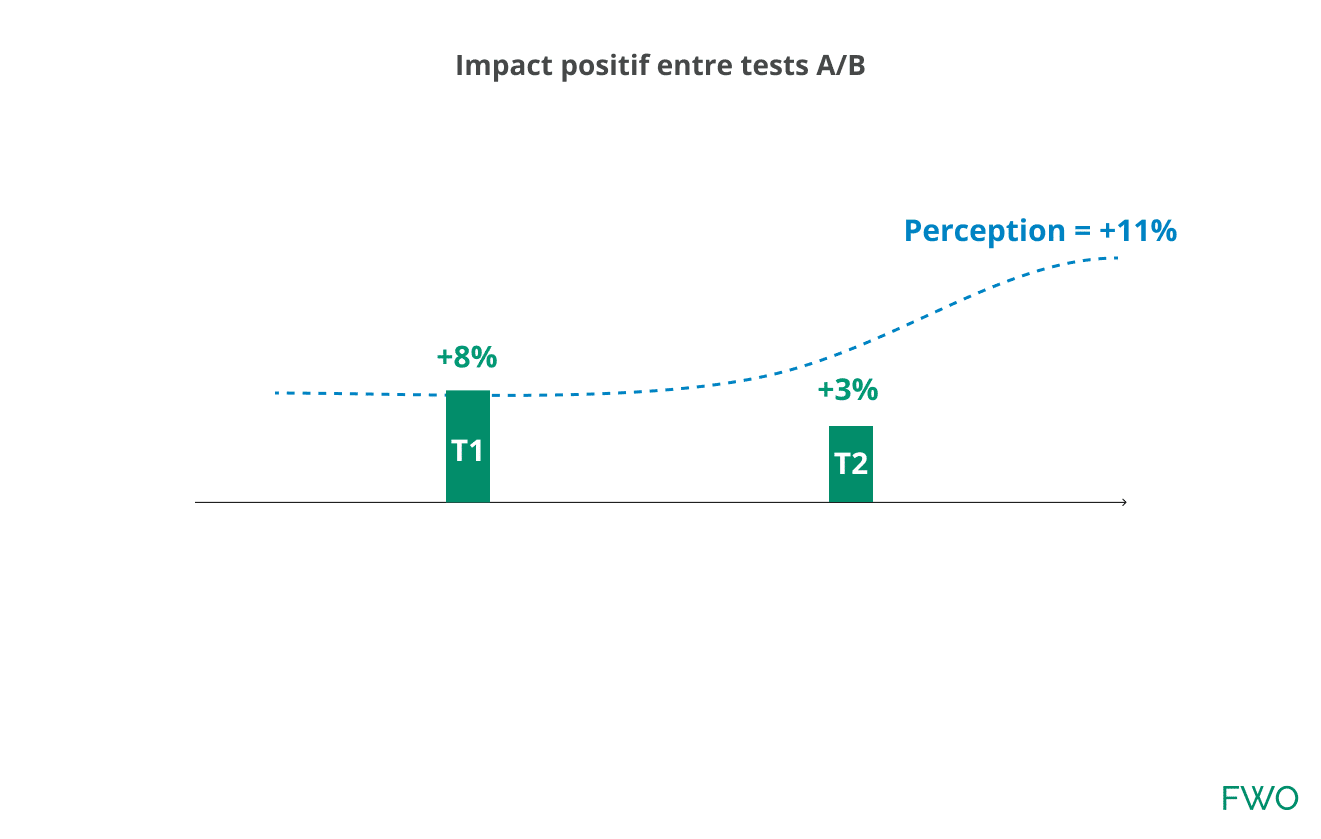
3) Impact positif : Le test A/B n° 2 est positif et augmente la perception de performance du test A/B n° 1 :
Plusieurs sessions entre les tests A/B
En allant plus loin dans la réflexion, cet utilisateur revient à plusieurs reprises (sessions) sur votre site. Cette fois, il ne passe plus par la page liste (test n° 1), mais directement par la fiche produit (test n° 2) avant de finaliser sa transaction.
L’utilisateur a pris le temps de s’habituer à la nouvelle interface du test n° 2, ce que l’on appelle l’apprentissage interne. À l’inverse, le test n° 1 n’a peut-être pas eu d’effet sur l’utilisateur.
D’un point de vue statistique, votre utilisateur est toujours marqué par le test n° 1 et se voit attribuer une transaction. Dans ce contexte, comment peut-on répartir l’impact des tests entre eux ? Le test n° 1 a-t-il un quelconque impact ?
Stabilité des résultats des tests A/B
Lorsque le trafic d’un test A/B est modifié, vos résultats perdent en stabilité pendant un temps. Ce comportement est normal lorsque vous désactivez une combinaison de test et que vous attribuez plus de trafic sur les combinaisons restantes par exemple. Les nouveaux utilisateurs qui entrent sur le test, le découvrent et doivent s’habituer.
Quel est l’impact sur des tests superposés avec un ciblage trop large ?
Si vous arrêtez le test n° 2 en fiche produit, l’utilisateur verra la fiche produit originale lors de sa prochaine visite. Cela peut modifier son comportement et les résultats de l’autre test A/B en cours.
Si vous arrêtez et lancez des tests souvent, vous réduisez drastiquement la stabilité de vos expérimentations. La seule solution pour pallier à ce problème est de lancer et d’arrêter tous les tests au même moment. Autant dire que ça n’a pas d’intérêt dans cette recherche de vélocité.
Segmenter les résultats des tests, la solution ?
Vous pouvez utiliser la segmentation Analytics pour mesurer l’impact d’une combinaison de test de manière isolée. Votre segment doit prendre en compte uniquement les visiteurs ayant vu la combinaison à analyser et la version originale de tous les autres tests.
Le volume disponible est fortement réduit et peut poser 2 problèmes. Le premier est la significativité de vos tests qui sera réduite à cause d’un faible volume. Le second est votre capacité à analyser en post-test et à découvrir des enseignements sur le comportement utilisateur. Par exemple, quel est le comportement du segment mobile ou des VIPs ? Le volume peut être très faible et vous serez incapable d’admettre certains enseignements.
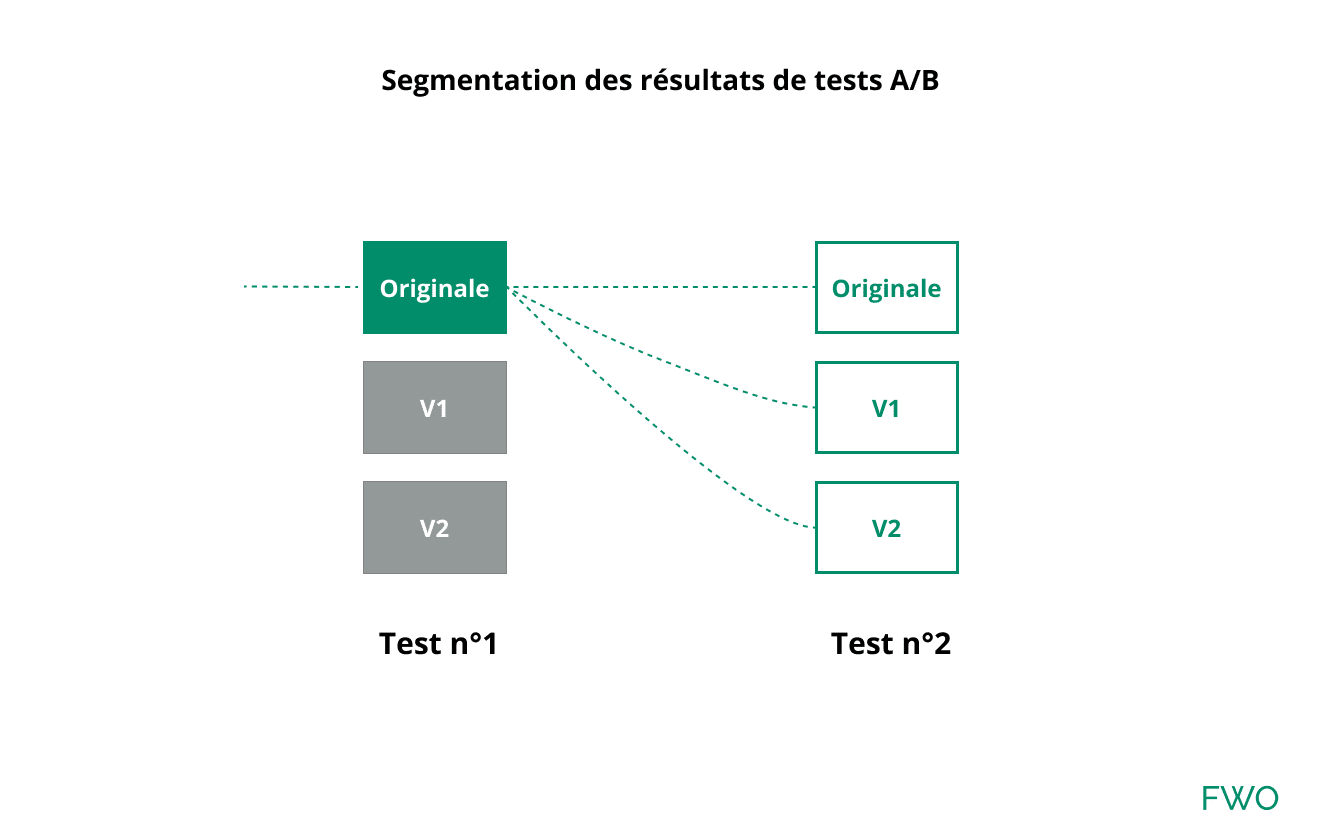
Utiliser cette configuration revient à lancer un test MVT géant, mais avec beaucoup plus de contraintes.
Comment organiser ses tests A/B ?
La meilleure solution consiste à lancer ses tests A/B ou MVT en parallèle. Vous pouvez soit créer des règles de ciblage pour tous vos tests (long) ou configurer votre outil pour qu’il accepte un seul test par visiteur. Des outils de testing comme ABTasty, Kameleoon ou Optimizely proposent cette fonctionnalité.
Les tests ne sont plus perturbés par des éléments extérieurs et vous pourrez segmenter vos résultats finement.
Augmenter votre potentiel de tests A/B
La première étape consiste à déterminer le nombre d’expérimentations que vous pouvez lancer par template, votre potentiel de tests. Cette information est précieuse et permet de prendre conscience de la difficulté à optimiser la performance d’une landing page ou d’une fiche produit spécifique par exemple. Je reviendrai sur ce point dans un autre article.
Le second point est de prioriser sa roadmap d’optimisation avec un système de priorisation objectif. J’ai entendu quelques remarques sur le temps que ce type d’exercice pouvait prendre pendant des réunions et le faible gain apparent. Sans priorisation, vous allez probablement lancer des tests longs à produire et/ou avec un faible potentiel. C’est ce type de test A/B ou MVT qui ralentit la perception de résultats et la vélocité d’un programme d’optimisation.

Enfin le point le plus important est de connaître la santé de votre équipe CRO et de son programme d’optimisation. Ça semble évident dit comme ça et pourtant, où en êtes-vous ? Avez-vous un goulot d’étranglement au niveau de la recherche, la conception ou de la recette d’un test A/B ? Le volume de tests gagnants est très faible ? Vous avez trop de demandes et peu de temps pour analyser la pertinence des hypothèses ?
Je vous conseille de suivre un indicateur global pour déterminer la pertinence de votre programme :

Plusieurs variantes sont imaginables et je reviendrai sur ce point dans un autre article.
Conclusion
Lancer plusieurs tests A/B en même temps n’augmente pas votre capacité à expérimenter, au contraire elle la ralentit ! L’impact sur les résultats est dramatique puisqu’il y a probablement de nombreux faux positifs. Aussi la détection des enseignements est quasi impossible ou aux mieux limitées. À terme, cette organisation CRO devient contre-productive pour la stratégie de l’entreprise en délivrant des constats faussés.
Ce travail d’accélération passe par une organisation structurée qui limite les idées les moins pertinentes au profit des autres. Il doit permettre d’accélérer toutes les autres phases : priorisation, impact des conceptions, limitation des bugs en production, ciblage adapté, automatisation de l’analyse ….
La communication et l’évangélisation de ces contraintes doivent être une priorité pour le leader CRO. Par exemple, communiquez sur un modèle de priorisation objectif et une roadmap permet de limiter les questions des autres équipes. Pédagogie et transparence !